タイタニック号生存者予測 - 特徴量の扱い
特徴量の扱い方について学んだことを本稿にまとめることを目的とします。 目的変数と説明変数をひとつひとつ確認することで考察していきます。
- SurvivedとPclassの関係
- SurvivedとSexの関係
- SurvivedとEmvarkedの関係
- SurvivedとCabinの関係
- SurvivedとAgeの関係
- SurvivedとSibSpおよびParchの関係
- SurvivedとFareの関係
- SurvivedとTicketの関係
- SurvivedとNameの関係
- まとめ
- 課題
今回は、kaggleのコンペティションに使用されたタイタニック号の生存者予測のデータを用います。
提供されるデータにはtrain dataおよびtest dataの2つがあります。train dataは予測モデルを構築するためのデータ、test dataには予測するためのデータ(生存情報なし)が格納されています。 今回のタイタニックのコンペティションでは、生存した乗客を予測することが目的となります。
まず、データの中身を確認します。train dataを表に示します。横軸に乗客の情報(特徴量)が並んでいます。縦軸が乗客数であり、891人がであることがわかります。
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt train = pd.read_csv("/Users/***/Desktop/kaggle/train.csv") train

それぞれの特徴量は、
PassengerId:乗客に付与された番号。kaggle側にて付与したものだと考えられますが、現段階では、生存率との相関関係は不明です。
Survived:生存結果であり、1が生存者、0が死亡者を表します。この特徴量を予測することが今回の目的です。
Pclass:乗客のクラス(ランク)を表します。1,2,3という番号がありそうです。
Name:乗客の名前を表します。
Sex:乗客の性別を表します。
Age:乗客の年齢を表します。
SibSp:乗客の兄弟、配偶者の数を表します。
Parch:乗客の両親、子どもの数を表します。
Ticket:乗客のチケット番号を表します。
Fare:乗客の運賃を表します。
Cabin:乗客の部屋番号を表します。
Embarked:乗客が乗船した出港地を表します。
現段階において、どの特徴量が生存率に影響するかは不明です。本稿では、これら特徴量と生存率の関係を考察していきます。
SurvivedとPclassの関係
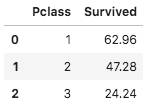
Pclassは乗客のランクを表す特徴量です。ランクが高い乗客であるほど、優先的に救助された可能性が考えられるため、生存率との相関が強いと考えられます。図1にPclassの分布を示します。
sns.catplot(data=train , x='Pclass', kind = 'count', ax = 'White', palette = 'Blues')

sns.catplot(data=train , x='Pclass', hue = 'Survived', kind = 'count', palette = 'gist_heat') plt.show() rate = train.groupby('Pclass')['Survived'].apply(lambda d: d.value_counts(normalize=True)*100) rate = pd.DataFrame(rate.reset_index()) rate = rate.loc[rate['level_1'] == 1] rate.drop('level_1', axis =1).reset_index(drop = True).round(2) plt.show()

SurvivedとSexの関係
性別の事前に想定される影響は、優先的に女性が救助される、もしくは、体力に勝る男性の生存率が高いが考えられます。図3に男性と女性の総数、図4に性別ごとの生存状況を示します。表3に性別ごとの生存率を示します。
sns.catplot(data=train , x='Sex', kind = 'count', ax = 'White', palette = 'Blues') plt.show() sns.catplot(data=train , x='Sex', hue = 'Survived', kind = 'count', palette = 'BuPu') plt.show()



SurvivedとEmvarkedの関係
Emvarked(出港地)が生存率にどのように影響するか想定することは難しいです。このような相関を持つか判断し難い特徴量の扱いには慎重になるべきだと考えられます。 まず、unique関数を使用し、出港地を確認します。
train['Embarked'].unique()
![]() ここで、SはSouthampton(イギリス)、CはCherbourg(フランス)、QはQueenstown(アイルランド)を表します。また、nanは欠損値であり出港地が不明な乗客の存在を表します。
図5に出港地ごとの生存状況、表4に出港地ごとの生存率を示します。
ここで、SはSouthampton(イギリス)、CはCherbourg(フランス)、QはQueenstown(アイルランド)を表します。また、nanは欠損値であり出港地が不明な乗客の存在を表します。
図5に出港地ごとの生存状況、表4に出港地ごとの生存率を示します。
sns.catplot(data=train , x='Embarked', hue = 'Survived', kind = 'count', palette = 'gist_heat')


図からC地点の乗客は生存率が50%を超える一方、他2つの地域は約35%の生存率と大きく異なることがわかりました。しかし、タイタニック号の航路についてwikipediaを確認した結果、3場所ともにヨーロッパと土地的差は見られませんでした。

sns.barplot(data=train , x='Sex', y='Survived', hue = 'Embarked', palette = 'Dark2') sns.barplot(data=train , x='Pclass', y='Survived', hue = 'Embarked', palette = 'Dark2')


図6、7では、barpltを用いて縦軸に生存率を示しています。グラフに表示されるエラーバーはグラフ頂点から95%の可能性でデータが含まれる範囲を表します。性別ごとに出港地の生存状況を比較した結果、性別に因らずC地点の生存率が高いことがわかりました。つまり、出港地と性別に疑似相関は認められません。 次に、階級ごとに出港地との生存率を比較しました。その結果、Q地点のPclass = 1,2において、エラーバーが0から1となり信頼できる生存率が取得できませんでした。この原因として、n数(Q地点でのPclass = 1,2の乗客数)が少ないことが考えられます。その総数をカウントした結果を下図に示します。
sns.catplot(data=test , x='Embarked', hue = 'Pclass', kind = 'count', palette = 'gist_earth') plt.title('Passengers of Embarked by Pclass', fontsize=20)

このグラフから、事前の推察の通り、n数が小さいことが確認できました。
この結果も含め、考察を行うと、Pclass = 1,2では、エラーバーが出港地に因らず重なることから、出港地と生存率に相関関係はみられません。しかし、Pclass = 3においては、S地点の乗客は生存率が他の出港地と比較し明らかに低いことがわかりました。
SurvivedとCabinの関係
train dataの概要から客室の情報に欠損値が確認できます。また、アルファベットと数字の組み合わせで表されることがわかります。Embarkedの調査と同様、unique関数を使用し、特徴量にどのうような値が格納されているか確認します。
cabin = train['Cabin'].unique() cabin = cabin.astype('str') print(np.sort(cabin)) print(train['Cabin'].isnull().sum())

この結果から、先頭のアルファベットはAからGまでであることがわかります。続く数字は1桁から3桁の数字であることが確認できました。また、欠損値は687個(77%)と非常に多いことがわかります。
先頭のアルファベットが生存率に影響を下図、表に示します。
train['Cabin'] = train['Cabin'].str[0] sns.catplot(data=train , x='Cabin', hue = 'Survived', kind = 'count') rate = train.groupby('Cabin')['Survived'].apply(lambda d: d.value_counts(normalize=True)*100) rate = pd.DataFrame(rate.reset_index()) rate = rate.loc[rate['level_1'] == 1] rate.drop('level_1', axis =1).reset_index(drop = True).round(2)


これら図表から、客室の存在により、生存率が向上していることがわかります。また、B、D、Eから始まる客室は生存率が75%程度と非常に高いことがわかります。また、客室の中で、Aの生存率は50%以下でした。タイタニック号の客室は下図のように上層から下層に向け、AからGに推移することがネット情報から確認できています。救命ボートは、デッキに搭載されていることから、Aの客室は他の客室と比較し、避難が容易であったと考えられますが、実際の結果は異なります。
これは、欠損値が多いためであると考えられます。欠損値は687個(全データは891個)あり、大半のデータが反映されておりません。これは客室のユニークな部屋数は147室であり、各アルファベットの層の客室番号に欠番が見られることからも推測できます。客室は生存率に影響し得る特徴量であるため、欠損値を補完し予測に用いることが望ましいですが、今回のように欠損値が大半を占める場合は不適切な相関を得る可能性があるため、特徴量として相応しくないと判断できます。
SurvivedとAgeの関係
年齢の分布と欠損値の数を確認します。
sns.catplot(data=train, x='Survived', y='Age', kind = 'swarm', palette = 'gist_heat') plt.title('Survived Rate by Age', fontsize=20) train['Age'].isnull().sum() out : 177

図から、死亡者と生存者で分布の形は大きく異ならないようにみられることから、年齢と生存率に強い相関はないと考えれます。また、欠損値は177個と少なくありませんので、扱いに注意が必要となります。
実際に年代ごとの生存状況のグラフと生存率の表を確認します。
train['AgeBand'] = pd.cut(train['Age'], 8, labels = False) train['AgeBand'] = train['AgeBand'] * 10 sns.catplot(data=train , x='AgeBand', hue = 'Survived', kind = 'count', palette = 'gist_heat') plt.title('Survived Rate by AgeBand', fontsize=20) rate = train.groupby('AgeBand')['Survived'].apply(lambda d: d.value_counts(normalize=True)*100) rate = pd.DataFrame(rate.reset_index()) rate = rate.loc[rate['level_1'] == 1] rate.drop('level_1', axis =1).reset_index(drop = True).round(2)


表から、0年代(0~9歳)では、生存率が高くなっており、優先的に救助された可能性が考えられます。反対に高齢層(60~80歳)は生存率が低く、極寒環境で体力が持たなかった可能性が考えられます。その他の年代では、生存率は約40%程度であり、891人全ての乗客の生存率と大きな相違はありません。
SurvivedとSibSpおよびParchの関係
ここでは、同乗した兄弟・配偶者の人数と親・子の人数をまとめて家族サイズとして評価します。この2つの特徴量は、兄弟か配偶者、親か子という重要とも考えられる変数が混在してしまっており、混在する情報をなくすため、家族サイズ(SibSp + Parch + 1)を新しいパラメータとして定義します。ここで+1は、自身の数です。
train['Familysize'] = train['Parch'] + train['SibSp'] + 1 sns.catplot(data=train , x='Familysize', hue = 'Survived', kind = 'count', palette = 'gist_heat') plt.title('Survived Rate by Familysize', fontsize=20) rate = train.groupby('Familysize')['Survived'].apply(lambda d: d.value_counts(normalize=True)*100) rate = pd.DataFrame(rate.reset_index()) rate = rate.loc[rate['level_1'] == 1] rate.drop('level_1', axis =1).reset_index(drop = True).round(2)


これら図表から、家族サイズが2,3,4人においては、生存率が高くなっており、その他家族規模では生存率は38%より低くなっています。しかし、家族規模4人以上では、人数が少ない(全数の5%以下)ため、n数として不足していると考えられます。また家族規模が11人であれば、11人の倍数のPassengerIdが得られるはずですが、実際には下の結果が得られました。
print('家族規模が4人である乗客の人数:{}人'.format((train['Familysize'] == 4).sum())) print('家族規模が5人である乗客の人数:{}人'.format((train['Familysize'] == 5).sum())) print('家族規模が6人である乗客の人数:{}人'.format((train['Familysize'] == 6).sum())) print('家族規模が7人である乗客の人数:{}人'.format((train['Familysize'] == 7).sum())) print('家族規模が8人である乗客の人数:{}人'.format((train['Familysize'] == 8).sum())) print('家族規模が11人である乗客の人数:{}人'.format((train['Familysize'] == 11).sum()))

この結果から、これらクラスに最低13個の欠損値が含まれます。仮に家族規模が11人である欠損値の最低4人が全員生きていると仮定すると生存率は50%を超えます。そのため、現段階では、家族規模により大きく生存率が変化するとは断定できません。
SurvivedとFareの関係
運賃ごとの生存状況を下図に示します。
sns.catplot(data=train, x='Survived', y='Fare', kind = 'swarm', palette = 'Dark2') plt.title('Survived Rate by Fare', fontsize=20)

上図より、100$以上の乗客では、生存率が高そうであることが伺えます。しかし、大半の乗客が100$以下に密集しているいることから、この区間を詳しく見る必要があります。
下記のように区分わけをします。
train['FareBand1'] = pd.cut(train['Fare'], [0, 25, 50, 75, 100, 1000]) sns.catplot(data=train , x='FareBand1', kind = 'count', palette = 'Blues_r').set_xticklabels(rotation=90) plt.title('Survived Rate by FareBand1 ', fontsize=20) train['FareBand2'] = pd.cut(train['Fare'], [0, 7, 7.5, 7.8, 8, 10, 15, 25, 35, 60, 100, 1000]) sns.catplot(data=train , x='FareBand2', kind = 'count', palette = 'Blues_r').set_xticklabels(rotation=90) plt.title('Survived Rate by FareBand2 ', fontsize=20) fare = train['Fare'].unique() np.sort(fare)


 Fareband1では0〜100$の区間を4分割しましたが、25$以下の乗客数が多数でした。そこでFareband2のグラフに示すようにさらに細分化しました。このグラフから、運賃には特定の範囲(7〜10$)にの分布が高くなっています。
人数を大まかに分けられたFareBand2について、生存状況を調べると下の図表になりました。
Fareband1では0〜100$の区間を4分割しましたが、25$以下の乗客数が多数でした。そこでFareband2のグラフに示すようにさらに細分化しました。このグラフから、運賃には特定の範囲(7〜10$)にの分布が高くなっています。
人数を大まかに分けられたFareBand2について、生存状況を調べると下の図表になりました。
train['FareBand2'] = pd.cut(train['Fare'], [0, 7, 7.5, 7.8, 8, 10, 15, 25, 35, 60, 100, 1000]) sns.catplot(data=train , x='FareBand2', kind = 'count', hue = 'Survived', palette = 'gist_heat').set_xticklabels(rotation=90) plt.title('Survived Rate by FareBand2 ', fontsize=20) rate = train.groupby('FareBand2')['Survived'].apply(lambda d: d.value_counts(normalize=True)*100) rate = pd.DataFrame(rate.reset_index()) rate = rate.loc[rate['level_1'] == 1] rate.drop('level_1', axis =1).reset_index(drop = True).round(2)


この図表から、10$以下の乗客は生存率が38%を大きく下回っており、10$以上で運賃に比例して生存率が増加する傾向が見られました。よって、運賃は生存率の特徴量として妥当であると考えられます。
SurvivedとTicketの関係
ユニーク関数でチケットの中身を確認しますが、数が多いため、ここでは、200個を表示します。
train['Ticket'].unique()[:200]

結果から、チケットの表記は数字の列および先頭にアルファベットが付与される場合がありそうです。そのため、アルファベットと数字の列に分け考えます。
まず、数字列から考察を行います。
Ticket_num = [] for idx, row in train.iterrows(): Ticket_num.append(row['Ticket'].split(' ')[-1]) train['Ticket_num'] = Ticket_num train['Ticket_num'] = train['Ticket_num'].replace('LINE', 0) train['Ticket_num1'] = train['Ticket_num'].astype(int) sns.catplot(data=train, x='Survived', y='Ticket_num1', kind = 'swarm', palette = 'gist_heat') sns.catplot(data=train, x='Survived', y='Ticket_num1', kind = 'swarm', palette = 'gist_heat') plt.title('Survived Rate by Ticket number1', fontsize=20) plt.yscale('log') plt.ylim(1,1E7)


左のグラフでは、数字列が桁数により大きく異るため、分布の形がわかりません。そのため、右のグラフでは縦軸を対数表示とすることで、桁数の変化に対しても分布を観察することができています。このグラフから、数字列は主に四桁以上であることが伺えます。また、10の5乗以上の区間では、数列のバンドが形成されており、先頭の数字のみで分けられる可能性が考えられます。
train['Ticket_num'] = pd.cut(train['Ticket_num1'], [0, 3000, 10000, 20000, 300000, 4000000]) sns.catplot(data=train , x='Ticket_num', hue = 'Survived', kind = 'count', palette = 'gist_heat').set_xticklabels(rotation=60) plt.title('Survived Rate by NumberBand', fontsize=20) rate = train.groupby('Ticket_num')['Survived'].apply(lambda d: d.value_counts(normalize=True)*100) rate = pd.DataFrame(rate.reset_index()) rate = rate.loc[rate['level_1'] == 1] rate.drop('level_1', axis =1).reset_index(drop = True).round(2)


この図表から、先頭が3であるチケットの生存率は基準生存率を下回ることが確認できます。また、1万台のチケットは生存率が高くなっていました。
2つ前のグラフ中ののチケット番号が100以下(外れ値と思われる)となる乗客の情報を確認します。
train[train['Ticket_num1'] < 100]

このデータフレームから100以下にプロットされたチケットは「S.O./P.P. 3」特殊なチケットでした。また、「LINE」という数字列があり、このチケットはFare = 0であることがわかりました。ここから、乗客ではなく、船員という新たな特徴量を考える必要性も考えられます。
そこで、運賃が0$である乗客(船員)を確認します。
train[train['Fare'] == 0]

船員であれば、出発地(S)から乗船すること、同乗した家族はいないことが推測できますが、全員この条件を満たしていました。この条件の場合、船員の生存者は一人のみであり、有意な特徴量であると考えられますが、これだけでは船員として少ないため他の条件も考慮する必要がありそうです。
続いて、チケットの先頭に付くアルファベットを考察します。
Ticket_str = [] for idx, row in train.iterrows(): Ticket_str.append(row['Ticket'].split(' ')[0]) train['Ticket_str'] = Ticket_str train['Ticket_str'] = train['Ticket_str'].where(train['Ticket_str'] != train['Ticket_num']) train['Ticket_str'].unique() sns.catplot(data=train , x='Ticket_str', hue = 'Survived', kind = 'count', size=4, aspect=3, palette = 'gist_heat').set_xticklabels(rotation=90) plt.title('Survived Rate by Ticket strings', fontsize=20)


ユニーク関数により種類を確認した結果、これら文字列に傾向は見られませんでしたが、STONやCAなど含まれるものが複数あることから、グループ分けはできそうです。また、「SC/Paris」から地名(出港地)の意味を持つ可能性が考えられます。
グラフの結果を見ると、各アルファベット列の頻度は非常に少ないことがわかります。頻度が最も多く、生存率が高い「PC」を持つデータを分析します。
trainPC = train[train['Ticket'].str.contains('PC')] trainPC.describe()

PCを含む場合、全てPclass = 1であり、運賃の平均値は全乗客の平均の約4倍でした。このことから、PCと生存率は疑似相関であることが考えられます。その他アルファベット列は、n数が少ないこと、アルファベット列の有無により一概に生存率が向上する傾向が見られないことから特徴量としては不十分であると考えます。
SurvivedとNameの関係
外国人の名前は大きくファミリーネーム、ミドルネーム、ファーストネームに分けられます。ファミリーネームを分析することで家族を特定できそうです。また、trainデータを見ると、ミドルネームにMr.やMrs.があり、一つの特徴量となりそうです。今回のデータセットにおいては、カンマ表記がされているため、先頭がファミリーネームとなります。
まず、ファミリーネームから確認します。
train['family_name'] = train['Name'].str.split(',', expand = True)[0] len(train['family_name'].unique())
out : 667
ユニークなファミリーネームの数は667個あり、ファミリーネームから生存率の考察を行うことは難しいと判断します。
続いて、ミドルネーム(敬称)を考察します。
train['honorific'] = train['Name'].str.split(',', expand = True)[1].str.split('.', expand = True)[0] sns.catplot(data=train , x='honorific', hue = 'Survived', kind = 'count', size=4, aspect=2, palette = 'gist_heat').set_xticklabels(rotation=90) plt.title('Survived Rate by Honorific', fontsize=20)


この結果から、Mrの生存率16%は、男性のみの生存率19%と大差なく、Mrs, Missの生存率(79%、70%)もまた女性のみの生存率74%と大差がないことを確認しました。
これらを除いた乗客の情報を確認します。
train.query('honorific not in ("Mr", "Mrs", "Miss")').describe()
この結果から、全乗客とMr,Mrs,Missを除いた乗客の生存率は後者が高くなりました。2つのデータ間での大きな違いは年齢と運賃です。2つのデータ間に平均値の差は見られませんが、中央値に違いが見られます。年齢は後者データでは9歳であり、幼子が多いことが確認できます。これは、「Age」の特徴量を扱った際の傾向(10歳以下では生存率が増加)と一致します。また、運賃の中央値は後者データでは29$であり、全乗客の運賃の中央値の約2倍でした。これもまた、「Fare」の特徴量を扱った際に見られた傾向(運賃が高いほど生存率が高い)と一致しました。
後者データの「Age」には欠損値が5つあります。欠損値補完の際にこの結果は有用であると考えられます。
まとめ
各特徴量について、それぞれ生存率を確認し、その結果から、下記の傾向が得られました。
1.全乗客の生存率
891名の乗客の生存率は約38%であり、この値を基準とし、特徴量の相関を確認します。
2.SurvivedとPclassの関係
Pclassの値が小さくなる(階級が上がる)ほど生存率が増加することを確認しました。Pclass = 1,2では基準生存率以上であり、Pclass = 3は基準値以下であり、生存率の説明変数として妥当だと考えます。
3.SurvivedとSexの関係
女性の生存率は約74%と、基準値を大幅に上回りました。反対に、男性の生存率は約19%であり、基準値を下回りました。この結果から、性別は生存率の説明変数として妥当だと考えます。
4.SurvivedとEmvarkedの関係
出港地がC(フランス)の場合、生存率は基準値を上回りました。Q(アイルランド)の生存率はほぼ基準値と一致し、S(イギリス:スタート地点)の生存率は基準値を下回りました。結果から、出港地は生存率の説明変数として妥当だと考えられますが、その根拠を実現象から想定できません。よって、これは疑似相関の可能性が考えられます。また、出港地は欠損値を2つ含んでおり、補完する必要があります。
5.SurvivedとCabinの関係
客室の特徴量は先頭のアルファベットと続く数字列の組み合わせであり、先頭のアルファベットは船体のフロアを表していることをタイタニック号の図面から確認しました。図面から、救命ボートが近い上層フロア(A>F)に近づくほど、生存率が増加すると考えましたが、その傾向は見られませんでした。理由の一つとして、Cabinは欠損値を687個(約78%)含んでおり、正確な傾向を反映していないためだと考えます。また、傾向が見られないことから欠損値補完も不能であり、客室は生存率の説明変数として妥当ではないと判断します。
6.SurvivedとAgeの関係
年代ごとに分けた結果、10歳以下は基準生存率を上回り、60歳以上の生存率は基準値を下回りました。10〜60歳では、生存率はほぼ基準値と一致しました。しかし、欠損値は177個あり、適切に補完した上で、生存率との相関を議論する必要があります。
7.SurvivedとSibSpおよびParchの関係
SibSpとParchは同乗した人数を表すことから一つの特徴量(Familysize = SibSp + Parch + 1)に変換しました。この結果から、家族規模が2,3,4人の場合、生存率が基準値を上回りました。単身または5人以上の家族の場合、生存率を下回る傾向が見られました。この結果から、家族規模と生存率に相関が認められそうですが、出港地の場合と同様直接要因を想定できません。よって、家族規模については、より深堀り(家族単位で生存するか家族の特定人物(子どもや女性)が生存するか)検討する必要があると判断します。
8.SurvivedとFareの関係
運賃が10$以下の乗客が約37%を占め、生存率は基準値を下回りました。10$以上の乗客は、運賃が上昇するにつれ、生存率が増加する傾向が確認できました。よって、運賃は生存率の説明変数として妥当であると考えます。
また、運賃が0である乗客を確認したところ、
9.SurvivedとTicketの関係
チケットは数字列と先頭の文字列(891枚の内230枚)で表されます。数字列は桁数および最初の数字で区分わけできそうであることを確認しました。数字列が2桁以下の乗客を確認した結果、運賃が0である乗客のがいることから、船員という新たな特徴量を検討する必要性が示唆されました。
文字列がPCである場合、生存率は基準値を上回りました。これら乗客の情報を確認すると、Pclassが全員1であり、運賃が高いという傾向を確認しました。しかし、文字列ごとのn数は少なく、文字列の持つ意味が不明であり、文字列ごとの生存率に見られる傾向は異なることから説明変数として妥当でないと判断します。
10.SurvivedとNameの関係
名前のファミリーネームと敬称に着目しました。ファミリーネームは667個の種類があり、この変数のみで考察は不能だと判断しました。敬称は、Mr、Mrs、Missは頻度が多いものの、それぞれ男性、女性の生存率からの変化は小さく特徴量として不適切であると考えられます。これらを除いた場合、年齢の中央値は9と大幅に小さくなりました。年齢の欠損値補完の参考にできそうです。
課題
今回、特徴量ごとに生存率との関係を評価しました。しかし実際には、第三の特徴量を介して擬似的に相関がある場合も考えられます。それらを考慮し、適切な変数に変換することを次回の課題とします。
また、予測を行うためには欠損値を補完する必要があります。最も簡単な補完処理は全数の平均値を代入することですが、欠損値が多いほど単純な補完では、実現象からずれが生じてしまいます。特に、今回のデータのように多数特徴量がある場合には、それら特徴量から補完する条件を絞り込むことも可能です。次回以降では、特徴量間の相関から欠損値を補完する方法について検討も行います。